
In this article:
For a lot of people, web users tracking remains something quite abstract, vaguely related to the ads displayed on websites, ads seemingly necessary to help the websites authors to make the website survive. They often also know that these ads often revolve around their centers of interests, like a seller in a shop where you have your habits and advising you on the products most suited to your tastes.
But all this is just the tip of the iceberg of a poorly legislated and controlled multi-billion dollars industry, in which advertisement is not the goal anymore but just a mean among others to make money.
The product is not what the ads try to sell you anymore, the product is you.
In this article, I try to uncover an industry crafted around the question how to extract as much information as possible from people’s lives and make profit out of it at any cost and in any way. We will first see who are the various actors behind users tracking systems. We will see that such industry is far more complex than what one may expect to. We will then see the various methods used to track the users. At last we will see the various method, both from the visitor’s and ethical webmaster’s side to protect people’s right to choose to protect their privacy.
Who are trackers
Trackers ubiquity
A tracker, as its name implies, collects information regarding you activity on a website, a mobile application, a wearable device and so on. Given a single standalone website or source of information, tracking technologies do not represent any real threat. A lot of people stop to this perception, but it is a wrong one.
![]() Think that more than 90% of the websites you are visiting, either
directly or indirectly (bundled content, etc.) rely on the services of often up
to a dozen different trackers simultaneously, on each of their pages.
Think that more than 90% of the websites you are visiting, either
directly or indirectly (bundled content, etc.) rely on the services of often up
to a dozen different trackers simultaneously, on each of their pages.
-
From the end-user perspective, the user has the impression to visit a sequence of independent and unrelated websites and services.
-
From the tracker perspective however, each of these websites report the activity of this very same and identified user. This allows tracking service to reconstitute the global user’s activity, expanding it beyond web browsing activity and covering well-known activity up to private or intimate activities, build a profile onto this and sell this information to anyone willing to buy it.
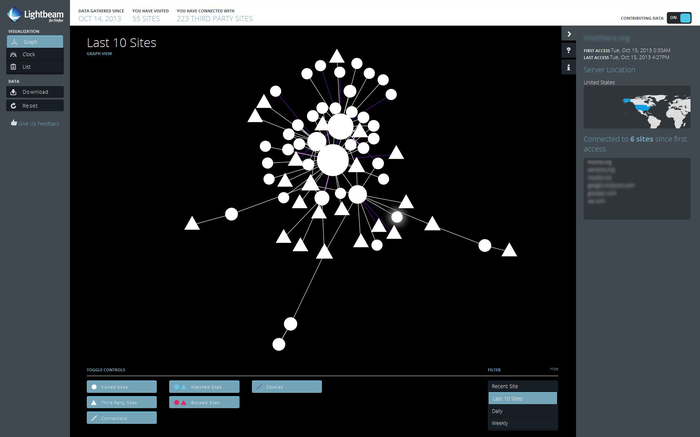
To easily explore the trackers behind the websites you are used to visit, you can use Lightbeam, a Firefox add-on by Mozilla, which collects the information as you browse the web and renders it as an interactive graph. However such module can only list the tracker themselves: while this still represent a valuable information, they only constitute the tip of the iceberg of a gigantic economy with an annual multi-billion turnover.

Note
Trackers are not limited to websites, but are expanding over every connected devices and applications.
A complex, opaque and uncontrollable ecosystem
The online advertising market generates billions of dollars per year, leading to the creation of a large and complex ecosystem dedicated to this domain.
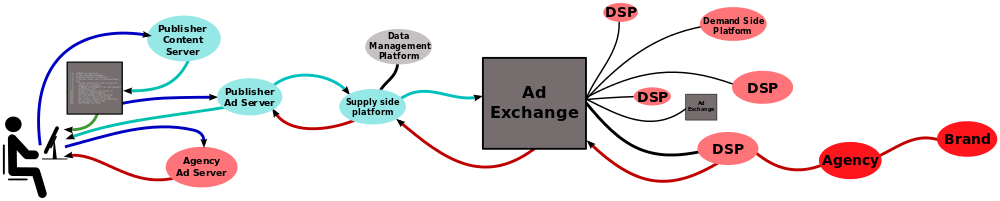
Usually, displaying a single advertisement involves five or more companies. Among them:
- The client wanting to buy an ad space, usually an agency acting on behalf of a brand (but as we will see in practice it could in fact be anyone).
- The publisher who owns the website where the ad will be displayed.
- The ad exchange platform allowing to put the ad space on auction through real-time bidding.
- The supply side platforms (SSP) allowing publishers to interface and manage transactions on several ad exchange platforms.
- Demand side platforms (DSP) allowing the client to submit their ads on several ad exchange platforms.
You can find more information and a nice diagram on Wikipedia.

Note
 For French readers, I highly recommend to read the issue #81 of the
MISC magazine.
It includes a special feature on web users tracking, written mainly by CNIL
and INRIA researchers, some excerpts being freely available.
For French readers, I highly recommend to read the issue #81 of the
MISC magazine.
It includes a special feature on web users tracking, written mainly by CNIL
and INRIA researchers, some excerpts being freely available.
Stéphane Labarthe and Benjamin Vialle, two CNIL auditors, also wrote another very interesting article in the issue #76 of the same magazine on web application information leaks usable for tracking purposes. The full article is freely available.
All these entities communicate in various ways, and at the core of their negotiations is the user’s profile. When a user accesses the publisher’s website, the ad exchange broadcasts several informations to all subscribed entities:
- A user’s unique identifier (the ad exchange tracking cookie).
- The page accessed by the user (URL).
- The categories the website visited by the user belongs to.
- Various other information on the user, including the first half of his IP address and his browser’s user-agent string.
This information alone already provides some tracking functionalities to entities passively listening such announces without ever actually pushing an ad or interacting in any way the the user’s system (in the MISC article mentioned above, researchers estimate that up to 27% of the browsing history can be reconstructed that way).
Legitimate subscribed entities are expected to put an offer. The offer amount depends on a lot of factors including the entity’s own strategy. The fact is that users for which a well furnished profile is available or users otherwise identified as being particularly valuable will require an higher offer, but on the other hand they will have more chance to actually click on the advertisement.
Note
A valuable target may be but is not limited to wealthy users.
Particularly vulnerable users are also valuable targets since they have higher chances to positively react to an advertisement designed to voluntary take advantage of their identified weakness.
This tells the importance of building and maintaining accurate users profiles, introducing us yet other actors in the market: profile enrichment companies and data brokers who correlate information related to the same user coming from various sources, allowing to better put user’s online activity in perspective.
The entity wining the real-time bidding auction wins the privilege to get the user’s browser redirected to its client infrastructure to fetch the actual ad. From a tracking point-of-view, this offers all the advantage you could have from the browser contacting your server as we will see.
For the other entities, the auction company often offers a kind of VIP offer where the browser will still be redirected to the client’s infrastructure but without any ad space available. The goal here is to allow subscribers of this offer to complete their profile database and increase their tracking abilities even on lost auctions or when they have no ad to display.
Why does this system exist
Users tracking networks is the result of the conjunction of two needs coming from both end of this network: the publishers on one side and the clients on the other.
Publishers perspective (webmasters)
Publishers do not feed tracking companies for the sole joy of feeding them. In some cases, they do not even realize the actual impact of such decision on their users privacy, they just follow technical trends generated and maintained by well crafted marketing discourses.
Publishers are encouraged to include some code snippets and links to third-party-resources inside their website’s page by various promises:
-
Live usability tests:
- Tracking users behavior through A/B testing programs.
- Record the user’s activity and actions so they can be replayed and studied.
-
Software maintenance and debugging:
- Performance reporting and profiling.
- Crashes1 and issues reporting.
-
Content hosting (we will see later that the advantage I list here may not be so evident in practice):
- Bundled videos and document viewers, allowing the visitor to watch an externally hosted video or a file without leaving the current website.
- Common libraries allowing the webmaster to take advantage of always up-to-date and fastly delivered Javascript files to add eye-catchy effects on his website.
- Common fonts usable for free and fastly delivered.
- Content delivery networks (CDN), allowing to duplicate website’s static content at several places of the Internet to deliver it faster to the visitor.
-
Add widgets involving third-party services (captchas, comments form, SSO, …).
-
Website monetization and traffic increase:
- Analytics libraries providing the webmaster free tools able to better shape visitor’s activity and optimize the website accordingly.
- Social networks icons allowing visitors to more easily share a page on their favorite networks.
- Advertisement allowing the webmaster to monetize his website.
A lot of these services are both advertised as “free” and backed by large fundings, making them look as the most obvious choice to reduce development costs while increasing impact and monetization.
However all of these services have a cost: end-users privacy.
Note
The fact that a particular service is paying or proposes a paid version (“professional” offer) does not imply that it is more privacy-friendly in any way. The common saying “If you’re not paying, you’re the product” is misleading.
The fact that a service-provider earns money by charging its customers does not mean he will rule out earning even more money by reselling collected data to third-parties.
Clients perspective (advertisers… and others)
There are several reasons why a tracker would like to track you:
- Anticipate your needs and actions.
- “Personalize” your browsing experience.
- Track you for the sole purpose of tracking you.
- Or, as a side-note, a malicious client could trick the ads network not only to track you but to distribute malware.
Let’s see each one of these use-cases.
Anticipate your needs and actions
This the original and most well-known usage of users tracking. The ad network, knowing your history and last events, tries to actively guess you next actions and bring relevant content to you.
In other words, starting from your input, it tries to anticipate your needs and actions, a bit like a forecast starts from current meteorological information as input and try to anticipate upcoming weather information.
Note
Don’t confuse algorithms making suggestions based on your activity on the same single website, like a VOD website relying on your viewing history and comparing it to its other users to produce meaningful suggestions list. As long as this is well made and allows you to effectively discover new interesting things you may miss otherwise, this remains a good and valuable service which raises no major privacy concerns.
But at the opposite the real issue begins when data becomes shared, when the VOD website to keep this example buys personal data about you from third-parties to create the suggestion list or sells your viewing history to external entities (the so-called “partners” in most websites’ privacy policies).
“Personalize” your browsing experience.
“Personalized experience” sounds good, isn’t it ? Marketing people are always skilled in finding great terms to designate gloomy things.
 “Personalized experience” means that two users browsing the same website won’t
see the same content.
In practice:
“Personalized experience” means that two users browsing the same website won’t
see the same content.
In practice:
-
Visitors perceived as wealthier may be directed to more expensive offers (as a travel agency did).
-
On a news or social service, depending on their identified profile (ideology, …) two users may be presented different articles or different versions of the same article to convey a given message more effectively. As explained by Glenn Greenwald following Snowden’s leaks, secret services are known to use this as a way of, to take GCHQ‘s own words:
Using online techniques to make something happen in the real or cyber world.
But such techniques are far from being reserved to state agencies as Trump hired a private company, Cambridge Analytica (potentially also linked with the brexit vote and Russian operations), to do precisely this kind job, in this case making his election happen. This comes as a great revelation and scandal to most medias, but it not as if Schneier saw such thing coming years ago…
-
In all cases such technology end-up in the creation of a filter bubble around the user, imprisoning him in an altered perception of the reality where he is rarely to never confronted to different opinions and point-of-views but is instead reinforced in his own ideology (in a more-or-less controlled way, see the previous bullet).
“Did Cambridge Analytica influence the Brexit vote and the US election? (The Guardian)
Tracking for the sole purpose of tracking
At last some of the clients of such tracking networks have nothing to sell you, they just pay for the tracking ability by itself. This include both public and private intelligence agencies, and in fact any entity willing to pay for this service with no real discrimination.
As we will see later, the GCHQ and the NSA are known to use such systems as part of their information gathering techniques, but they are not the only ones and such use is not even limited to large companies.
Researchers of the University of Washington have demonstrated that a budget of only $1,000 is enough to track someone’s location through the ads network, making such practice affordable to virtually anyone.
![]()
A word about malvertising
We saw that, in particular when dealing with ads networks, webmasters were including code on their websites ultimately coming from an unknown and uncontrolled source (the infrastructure run by the winner of the ad auction) and executing on the visitor’s browser.
Could such a client winning the ad auction be downright malicious and distribute, instead of innocuous advertisements, malware code?
Yes, such things happens.
Such cases nevertheless remain quite rare as they undermines the ad exchange platform credibility in the eyes of the publishers (from the uend-user’s point of view his computer was infected while visiting the publisher’s website, this is not good for the business).
Ad exchange platforms therefore do their best in taking care of checking the sanity of the entities subscribed to them and attempt to apply strict rules regarding sub-syndication. An example of this can be found in Google’s DoubleClick ad exchange documentation:
Google has developed proprietary technology and malware detection tools to regularly check creatives2. Fourth-party calls or sub-syndication to any uncertified advertisers or vendors are forbidden. Our automated malware checker scans all creatives. Any ad that we detect distributing malware will be pulled to protect users from harm. Any Ad Exchange buyer whose creative is found to contain malware is subject to a minimum three-month suspension.
However, a recent case of malvertising affecting Google’s DoubleClick network and YouTube website demonstrated that, as efficient as they can be, such automated checking can still be bypassed.
Moreover, in its section on pharmaceutical products ads, due to the complexity of the ad networks and the number of intermediaries involved, Google acknowledges the lack of visibility on the actual identity of the client behind a particular ad:
On Ad Exchange, the relationship is with the buyer and we lack insight to the identity of those advertisers.
So, while relatively rare compared to other threats, malvertising is certainly not going to disappear soon.
How tracking is accomplished
In its simplest form, user tracking consists in assigning a unique ID to a user and record when and where on the Internet this ID pops-up again. However, due to limitations imposed by this scheme, in particular the easiness for a user to delete such ID, more advanced techniques “had” to be found.
We will see how far tracking companies put their creativity in order to solve this “problem”.
Cookies “and similar technologies”
The most straightforward way to track a user is by storing a unique identifier in his browser, and that’s precisely what cookies are for.
Cookies are not tracking objects by nature. They primarily goal is to implement the notion of states in the stateless HTTP protocol. Cookies allow things like remembering that you have an open session on a website, adding goods to your basket before even logging-in, remember website-specific settings and preferences. But in the case which occupies us here, they will allow to remember a unique identifiers assigned to you.
A lot of users however now either drop or refuse cookies. For instance they may configure their browser to clear all cookies when closing the browser or refuse all third-party cookies.
So here enter what tracking companies coined as “similar technologies”. This intentionally very vague term covers various techniques, such as:
-
Flash cookies (LSO), when the Adobe Flash plugin is enabled in the browser (less common nowadays).
-
HTML5 provides the local storage feature when JavaScript is enabled (the default and most widespread behavior, usually not even deactivable without third-party browser plugins).
However, all those techniques make it trivial for the user to see the tracking objects assigned to him and to potentially delete them.
Another solution is to abuse the browser’s cache behavior to store identifiers. This can be done through several ways:
-
By caching a page or resource linking to another resource with a unique identifier appearing in its URL (
?id=12345for instance).The first time the user visits the page, this page or resource is generated and assigned a long cache period. The next time the user accesses the page the browser will reuse the cached version, and therefore reuse the same identifier.
-
A web server can also assign an ETag to a particular resource. An ETag is a free-form resource identifier which is changed as soon as the corresponding resource is modified. Once the cache period of this resource expired, the browser can send this ETag to the web server so the latter will send the new version only of the resources has indeed be modified, and save bandwidth and loading time otherwise.
Generating a unique ETag for each new user associated to a short cache time will make the browser to send the unique ETag to the server each time the resource is linked, turning the ETag into an effective user tracking mechanism.
Tracking users without storing any ID
As long as the identifier is stored in the browser, this leaves the ability for the user to delete it. The most effective tracking technique is therefore the one which doesn’t involve any storage at all user-side and is hardly detectable or avoidable.
Note
You will notice the doublespeak of advertisement companies, publicly communicating on user’s freedom to opt-out from tracking while feeling the need to technically bypass opt-out measures.
Due to the amounts at play, online advertisement is a very competitive market and involved companies cannot afford to be left behind by letting users massively opt-out of their services. Publishers and clients just go to the companies offering the highest return on investment, this implies targeting ads, which implies knowing the user to some extent.
This is why the DNT header, proposed as a standardized way to allow users to opt-out from online tracking, generated so vigorous discussions among standardization organisms, advertisement companies and browsers editors3.
Password field autofill
I was already grumbling on how most browsers still autofill authentication forms by default in a previous post. It is no surprise that users tracking company attempt to exploit this behavior too.
The idea goes as follow:
-
The tracking script injects an invisible authentication form in the page the end-user is currently visiting.
-
If one credential is known, the browser will by default and without any user interaction or information fill the authentication form fields.
-
The tracking script now just has to read the content of the login field and send it back to the tracking company systems4.
This method only works on users storing their credential in their browser and who do not have disabled the autofill feature. I can guess this covers only a fraction of the web users, however, the resulting ID is a very strong identifier: reliably and tightly tied to the user, independent from the device or software used and very rarely changed. It really worths the effort for tracking companies to collect it.
Nevertheless, for all the other browsers remains a very efficient technique called browser fingerprinting.
Browser and canvas fingerprinting
 Browser fingerprinting relies on the association of several non-unique
properties of the user’s browser which, mixed together, allow to obtain a
unique global signature.
Browser fingerprinting relies on the association of several non-unique
properties of the user’s browser which, mixed together, allow to obtain a
unique global signature.
This technique relies on a wide range of properties:
-
Among the most effective are the fonts list and plugins list as they directly depend on the software installed by the user on his environment.
-
Other widely used properties are the browser’s user-agent string, the platform name, accepted file format and encoding, the screen resolution, the preferred language, the timezone, checking whether various browser settings are enable or not, and the list goes on…
But, still in the realm of browser fingerprinting and often associated to the other properties is canvas fingerprinting.
Canvas is a low level HTML5 element allowing a script to render 2D images.
The exact final result may depend on a lot of factor which may not be easily alterable by the user:
-
Fallback fonts.
-
Emojis rendering (emojis are unicode single characters, such as “😃”, whose representation usually depends on the system and the version of the system used5).
-
Pixel level rendering will differ on device sharing identical software stack but different hardware, notably because of the graphical cards, the CPU and the drivers being used. Such difference is not noticeable to the naked eye, but enough to result in a reliable and different fingerprint6.
Note
Most of these methods relying on JavaScript, you may wonder whether disabling JavaScript might allow to circumvent such tracking. The answer is no, not really.
Browsers with Javascript disabled are fairly uncommon, so the fact you are using a browsing with JavaScript disabled will just be part of the fingerprint tracking you.
This technique has two great advantages from trackers perspectives:
-
It is usually complex, of not impossible for users to provide a fingerprint,
-
This technique starts to implement a new concept: the malleability of the tracking token. After an update, a configuration change, or even a ham-fisted attempt to alter the fingerprint, the browser’s fingerprint will never change both at once and at 100%, meaning that at a given time there will still be enough constant information to link the old and new browser fingerprints.
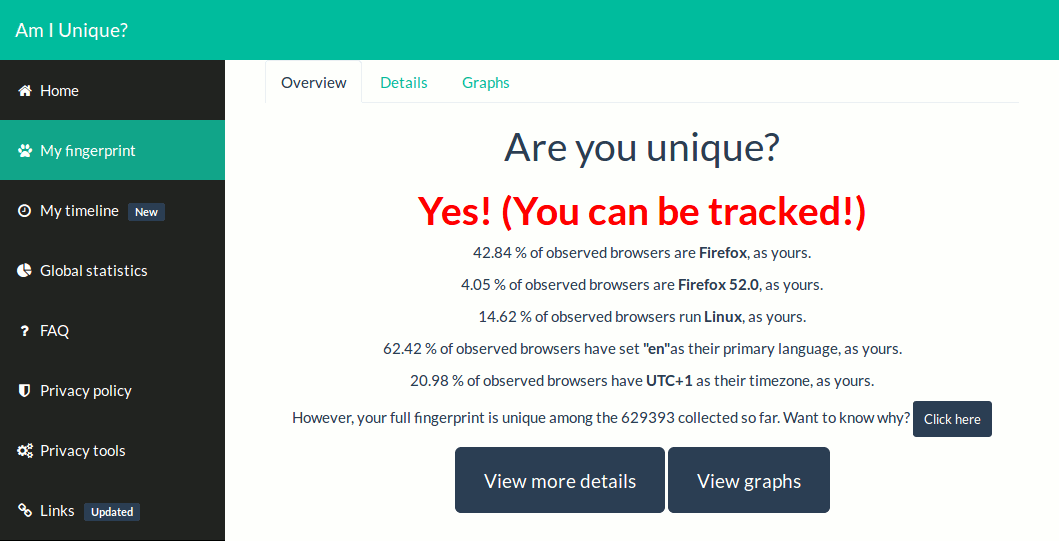
A few websites such as Am I Unique? (recommended) and EFF‘s Panopticlick allow you to study and play with this technique.
Session replay scripts
When a company tracks your activity, what does the term “activity” really covers in this context? You would be ill-advised to consider it limited to things like clicked links, submitted forms and the content of your shopping cart. Ars Technica reported a study revealing the increasing use of so-called session replay scripts:
These scripts record your keystrokes, mouse movements, and scrolling behavior, along with the entire contents of the pages you visit, and send them to third-party servers. Unlike typical analytics services that provide aggregate statistics, these scripts are intended for the recording and playback of individual browsing sessions, as if someone is looking over your shoulder.
Such scripts are used to allow live usability tests, and allow to both record and follow in direct all of your interactions with such monitored websites including keystrokes on non-submitted forms.
While some of these monitoring websites try to limit the recording of personal information such as passwords, credit card numbers and personally identifiable information, the study shows that they do so imperfectly, when they do it at all. Apart from that everything else get recorded and transmitted. In particular such scripts break the assumption that the content of a form will be sent to the remote server only once you submit it: as soon as and as long as a webpage from such site remains open, you are being monitored.
While such scripts already existed, until now they were classified as malware and part of users spying tools at the same level as keyloggers for instance. Things going in this direction, with a bit of sarcasm I could predict it won’t take long before software such as BeEF, currently an offensive browser pentesting tool, will become officially marketed as a web development and user experience improvement tool…
Tracking ID correlation
The various techniques described until now allow to create one tracking token each. However, there are various advantages in creating and handling several of such identifiers:
-
To increase the malleability of the tracking system, a concept we introduced when covering browser fingerprinting.
-
To implement cross-device tracking and manage to recognize and track the same user independently of the device used.
-
To allow several companies to share information on a given individual.
Zombie cookies
In the previous session we saw various ways to track a user. What if, instead of selecting one single method , we would use several or all of them simultaneously? This way, would a tracking system become somehow unusable the other ones would be able to restore the missing information.
This exactly how zombie cookies work.
Various browsers add-ons and settings allow a user to delete his cookies or limit the effect of some forms of tracking. Zombie cookies brings resilience against users attempting to opt-out from tracking by allowing to recreate deleted cookies.
-
Let’s say a new user comes in, a new unique ID is affected to him, stored in two places in the browser.
-
The user clears one of the places, as an attempt to opt-out from tracking.
-
Relying on the second identifier which hasn’t been deleted, the tracking company is able to “resurrect” the deleted one.
Note
A class-action was filed against several trackers which were using this technique, evidence showing how these trackers were always respawning cookies with identical values despite manifests efforts from the end-user to delete it.
To address, this respawned cookies now bear new unique values, but this does not imply in any way that they are not linked to the same unique user’s profile in the tracker database (ie. the “new” value may just be generated as synonym of the previous one and linked to it).
 But marketing companies are not the only ones interested in zombie cookies.
The NSA had the project to use Evercookie, an open source
implementation of the zombie cookie mechanism, to track the users of the
TOR anonymous network:
But marketing companies are not the only ones interested in zombie cookies.
The NSA had the project to use Evercookie, an open source
implementation of the zombie cookie mechanism, to track the users of the
TOR anonymous network:
-
Assign a new set of cookies to the target while it is accessing certain resource anonymously, protected by the TOR network.
-
When disconnecting from the TOR network, the browser does some cleaning, hopefully incompletely (the Evercookie reports the use of 17 different systems to store the unique ID on the browser).
-
When the user now connects to the web normally, cleaned cookies are recreated and the now identifiable user can be linked to the anonymous activity made on step 1).
Cookies syncing and retargeting
A single user usually have dozens of different ID associated to him:
-
Different companies involved in the ad network may use different ID schemes and assign different IDs to the same user.
-
The same company may assign additional IDs to he same user because he was not immediately recognized as already known to the database or for legal reason (see the note about zombie cookies above).
-
The same user may use several applications (an email client and a browser for instance) which do not share a common cookies database.
-
The same user may use several devices (personal and professional computers, cellphones, tablets, etc.), each one with their own cookies and fingerprinting information.
“Fortunately”, this doesn’t mean that information about the user is scattered as solutions exist to solve this “issue”.
Retargeting
Retargeting occurs at the scale of a single tracking company.
The idea here is to trigger and tune the tracking following certain actions:
-
Opening an email (usually thanks to the presence of external images) or clicking on one of its link. The latter one is particularly powerful as it not only confirms your email address to the tracking company but also links it to tracking tokens associated to you browser.
-
Clicking on a link controlled by the tracking company (the link doesn’t directly point to the destination but redirect you to the tracking system in between to tag you).
-
Using certain keyword on a search engine.
-
Visiting certain websites.
Cookies syncing
Cookies syncing, also known as cookie matching is the action of linking two previously unrelated IDs which now become synonym, the associated profile information being subsequently merged.
-
These IDs may belong to the same tracker company.
This happens typically when an unidentified user is recognized as being already known to the database, whether because he authenticated himself to open a session on some website, opened an email or clicked on a link in it, etc.
This is notably a good way to implement cross-device tracking.
-
But these IDs may also become to different companies.
Different companies maintain specific correspondence tables allowing to share information about a user efficiently, making the information collected by one company to be able to enrich the profile of the same user hosted by various other companies (we will soon cover profile enrichment services.
This allows to implement wide-scale tracking.
One important property of cookie syncing is its retroactivity. Every actions tracked while you weren’t identified can now be merged to your main profile, updating it to associate these actions to your recorded identity.
To give a concrete example, when you use some well-known and popular SSO service, your identity confirmation is extended to all websites visited during the browsing session, both after and before authentication, not only the website where the authentication occurred.
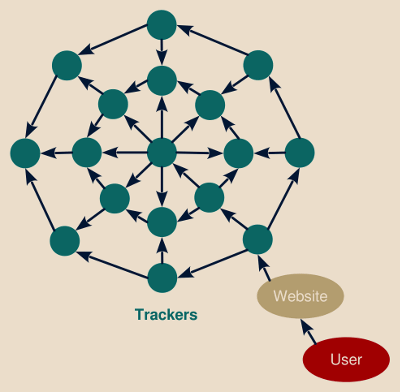
The association of techniques such as zombie cookies, cookies syncing and information sharing allows to build a tracking far more able to pass cross-device boundaries and resist to users’ opt-out attempts. It follows a spider web pattern, were identification and profile information is propagated from one company to another following the various commercial and subsidiary partnerships.

As Steven Englehardt stated it:
Starting a truly fresh browsing profile is a very difficult task the web never really forgets.
Note
Often, front-end tracking services explain that they only collect “non-identifiable” information. Thanks to cookie syncing and information sharing, back-end services can still concatenate the information collected this way to perfectly identified profile databases.
Data brokers and profile enrichment services
We saw until now how tracking techniques could capture fine-grained users actions (see session replay scripts) while operating at a wide-scale level (see tracking ID correlation), and how such tracking could cross devices and opt-out attempts.
There is still a limitation to such infrastructure: it can only record data provided at one time or another by the user himself. But, as an attempt to “still better serve their users”, marketing companies have the solution : data brokers and data enrichment services.
Data brokers are located toward the core of the spider web pictured in the previous section. They do not produce any advertisement to display to the end-user. In fact, they never directly interact with the end-user’s system. Their whole job is just to collect, correlate and distribute information to allow other companies to crosscheck and complete their profile databases.
Data brokers information sources go way beyond the ad exchange networks we saw until know. They play in a poorly legislated land and actively harvest potentially thousands of public and private sources for users information, depending on how much their customers are ready to pay.
Wikipedia provides an interesting list of examples of such information sources:
- Census and change of address records.
- Motor vehicle and driving records.
- User-contributed material to social networking sites such as Facebook, Twitter and LinkedIn.
- Media and court reports.
- Voter registration lists.
- Consumer purchase histories.
- Most-wanted lists and terrorists watch-lists.
- Bank card transaction records.
- Health care authorities.
- Of course, web browsing histories.
- And the list could go on…
CBS, which proposes an interesting article about this business, also notices:
Acxiom claims to have files on 10% of the world’s population, with about 1500 pieces of information per consumer. […]
Individuals generally cannot find out what data a broker holds on them, how a broker got it, or how it is used. Some data brokers retain all information indefinitely.
The collected information is very varied and heavily depends on their client need and budget, and includes information such as: birthdate, gender, height, weight, ethnicity, marital status, sexual orientation, shopping habits, links to social medias accounts, direct or indirect relatives (online contacts, address book, people visiting or living in the same area or visiting similar websites), political, philosophical and religious affiliations, financial information (household income, net worth, home ownership status, investments), employment information (job title, company size), health, personal issues (alcoholism, addictions, depression).
Note
Databases such as this are primary targets for attackers to build identity theft operations.
However, while such data may be very personal and valuable to you and cause you trouble years after it get stolen, it just worths “pocket money” to such company gathering it, giving them very few incentive to take any initiative to properly protect them.
Moreover, before even thinking about data protection, the tracker should at least have a minimum understanding of the potential impact of the data he owns. This is not always the case as shown when Strava, a social network and mobile app used to track athletic activity, inadvertently published the location, maps and patrol routes of military bases in sensitive zones and conflict zones…
At last, as highlighted by Kalev Leetaru, the quality of the collected data may vary considerably, but I share his worry about banks and insurance companies which may start to take decisions about you and your life based on wrong data…
How to limit tracking
As we saw in this article, the limit between malware and user profiling is becoming less and less clear. Government-like intelligence technique are now used for marketing and audience influence purposes, all this outside of any effective regulation and without even any clear view on the identity of each actor and their actual inter-relations.
The question one could ask is how to avoid tracking? The answer is you cannot, at least not completely, but it can be reduced to a saner level.
Advices for end-users
There are plugins and software allowing you to alter your browser’s properties to avoid tracking by making your browser blend into the crowd. Such solution however doesn’t work reliably:
-
More often than not, you will end-up with an odd set of properties making you stand out of the crowd and more easily identifiable, the exact opposite of the pursued goal.
-
Moreover, the association of technologies such as browser fingerprinting, zombie cookies and cookies syncing are very powerful to avoid such opt-out attempts.
If you really want to follow this route, the only solution is to use the default setting of a common browser on clean and default installation of an operating system and ensure all network activity goes through a public VPN. This is basically what anonymity-focused systems such as Whonix and Tails are doing, but this is often not practical for the general audience.
The most efficient way to avoid tracking is to not talk to the tracking servers in the first place. The main sources of worrying you will have to check are as follow:
-
Advertisement and other optional features: The easiest solution is to simply block them altogether.
Plugins such as uBlock Origin and Privacy Badger are available for most browsers and allow you to easily escape most trackers. Apps may also be available for your phone and tablet, like AdAway for Android devices.
Note
There is no problem in using uBlock Origin and Privacy Badger in parallel. While the former has stricter and more efficient rules, the latter automatically replaces social networks buttons by privacy-friendly alternative on websites which haven’t done it yet.
If you are tech savy, you can also setup a DNS sinkhole to protect your network as a whole. This may also help to fight against various other threats.
-
Third-party resources and services: While they are sometimes used for optional feature (a more stylish font, some eye-candy JavaScript effect, etc.), these resources are often required for the service to function properly and cannot therefore be blindly blocked.
Fortunately, a plugin such as Decentraleyes allows to limit the effectiveness of such tracking by intercepting requests to the most commonly used resources and serving a local copy instead.
-
Browser own settings and behavior: Independently from the visited website, your browser itself may also report your activity to a third-party, in particular he may send each and every URL you visit to check for potential phishing and malware websites.
You may want to disable such feature for privacy reasons, but by doing so you will loose the associated protection, so it is a trade-off you have to decide.
-
Anti-virus web protection: For the same reason as the browser, your anti-virus software may also intercept your queries and send them to their parent company for approval before letting you access the desired page. Depending on the manufacturer, such data can potentially be shared with third-party companies.
Note
The anti-virus software is at a privileged place to collect all kind of other data, such as the content of document files and the list of installed or running software.
As always, there may be no problem in this… as long as this data remains between you and your anti-virus editor and is not shared with unknown and untrusted third-parties.
The Am I Unique? website provides good recommendation to help you escape from tracking. On a more general perspective, you may also be interested in the software recommendation lists maintained by PRISM Break and PrivacyTools.io. I will also soon write a post on Firefox hardening, which will describe various privacy enhancement.
At last, some websites voluntary prevents you from accessing their services as long as you don’t disable anti-tracking features from your browser, displaying a nag-screen asking you to “Allow advertising” as they usually present it.
-
You can take this as an equivalent of the anti-phishing and anti-malware nag-screens preventing you from accessing a potentially dangerous page. Here the website presents itself as not caring about your privacy, which can reasonably be interpreted as a dangerous behavior, and to protect your privacy the website takes the initiative to lock you out of their service. How nice and honest of their side, risking to loose visitors for the sake of privacy! Simply move on to another equivalent and privacy friendly service.
-
If for some reason you cannot switch to a more privacy friendly alternative, you can temporarily disable anti-tracking features just for this tab, the ideal being then to open it using Incognito or Private mode (this article explains how to do it with various browsers).
-
Alternatively, you can also start a new browser’s window using another, distinct user profile (using the
firefox -pcommand) to get a new browser window with no plugin, no history and back to factory settings.
Advices for webmasters
The users of your website entrust you some of their data. You have a moral obligation to ensure that this trust is not abused.
Beyond the moral obligation, you are also often bound by law8 to bring your users guaranties about where and how their data are being processed and detail them explicitly in your privacy statement and when collecting users’ consent.
When using tracking services, no matter what their initial “advertised” purpose is, you often lack visibility on these aspects, making you potentially liable.
Note
Even if you don’t value privacy for yourself, this does not mean you should impose this choice to your users.
When designing a service of any sort, always ensure that the end-user stays in control.
General advices
You must remain conscious that each time you include some third-party code on a page, you are effectively giving the control on that page to this third-party9, both from a technical and a legal point-of-view.
-
From a legal perspective, it is you job to check precisely which data is collected by the third-party, where it is stored, with who (and where) it is shared.
You are enticed to inform your users about this, depending on your jurisdiction either through your privacy policy page or by collecting their explicit agreement and you must maintain your documentation in coherence with the one the third-party, notifying your users of any changes on the third-party side which may impact them.
-
From a technical perspective, you must document each dependency you have toward third-party actors, and in particular you must follow completed contracts and ensure that the matching is properly removed from the website.
-
You should handle exceptions and not include third-party code on pages containing sensitive information, such as subscription and login pages.
Advertisement
In an interesting article published on Lifehacker by Alanhenry, Rainey Reitman, activism director at the EFF, explains that:
Privacy advocates aren’t fighting for an ad-free Internet, they just want to give consumers who care about their privacy a way to opt-out of behavioral and targeted marketing efforts, something industry groups are fighting them on tooth and nail. […]
While the basis of revenue-generation on the internet has always been advertising, it’s only been recent years that we’ve seen a massive shift towards behavioral and targeted marketing that sticks with individuals not just on a single page, or in one company’s services, but across all of their activities online.
While I agree with the underlying idea, I don’t necessarily share the same belief that “the basis of revenue-generation on the internet has always been advertising”.
I remember a time before advertisement began to pollute the browsing experience. Even nowadays:
-
There are still people willing to build free or donation-based quality content (see the Wikipedia project for instance).
-
A lot of commercial companies are now coming back from their dream of living only from ads (see all those news websites now requiring monthly fees to be able to read the most recent articles in their entirety).
Some websites still directly include provider’s advertisements on their website (the good old way). Such ads are not blocked by any ad-blockers and avoid shady chains of intermediaries thus limiting the risk of data misuse or malvertising.
Social buttons and third-party content
Various technical ways exist to integrate social buttons and third-party content like embedded videos in a way which requires no initial automatic loading from the third-party service. Loading usually occurs only when the user explicitly interacted with the object (pressed the “Like” button, clicked on the video preview image to start it, etc.).
Moreover, I never really understood the hype about third-party hosted fonts and JavaScript libraries. The arguments usually presented are the following ones:
-
Better transfer speed thanks to…
-
… cache match: The page will display faster for new visitors as the fonts and JavaScript libraries will already be present in the browser’s cache from previously visited websites also using them.
But this is wrong due to fragmentation of the various libraries and versions in use.
-
… browser parallelism: This arguments mainly dates back to the era when browsers opened by default a maximum of two HTTP 1.0 connection to each web servers. A web server being identified by its host name, storing content on as many third-party hosts as possible allowed to force the browser to increase the maximum number of simultaneous connections, thus potentially increasing the overall download speed.
Nowadays web browsers allow 6 or more HTTP 1.x connections in parallel to each web servers, already strongly reducing the issue and making the usage of such method to enforce parallelism much more questionable. But more importantly new protocols such as HTTP/2 (and the deprecated SPDY) offer efficient multiplexing features which exceed the performance gain one could expect by using such old trick.
-
… optimized files content: Compared to their standard versions, the content of the files proposed by these specialized services has been optimized for smaller transfer time.
In practice, the resulting files are just a few KB smaller than their standard counterpart, this won’t make any noticeable difference even on mobile devices.
If size matters, you may better try to avoid building 20+ MB pages to display 3 KB worth of text and configure your web server to set sensible caching headers.
-
-
Improved compatibility: This is plain wrong, as such third party files:
- Fail with some browsers,
- Fail on some networks,
- Fail in some countries (or see here for the official documentation).
If compatibility is a real concern, either implement a fallback mechanism allowing to download files from your server when the third-party ones are not available, or simply don’t use a third party at all.
-
License and ease of use: The fact that a certain file is stored or has been selected to be hosted by a third party doesn’t really solve any problem compared to other free fonts sources for instance and you still need to apply the same care as everywhere else.
If you need to find free fonts, simply head to some reputed websites such as Font Squirrel where you will be able to filter available fonts depending on their license and be proposed to download ready-to-use packages for your website.
Building and enriching users profile
When old-fashioned websites wanted to collect information from their visitors, they used to have surveys. Now the information is extracted “by force”.
Good surveys are not necessary boring to fill, techniques such as progressive filling10 can make it lighter and a natural part of using the service.
Of course, there are intimate questions that users may hardly openly answer in a survey as long as they seem unrelated to the service they expect. But in that case, if you would not ask some information in person to someone, why use indirect ways to obtain it?
Doing background researches in the back of your users doesn’t seem sane.
Reselling the information that your users entrusted to you doesn’t seem sane.
Behavioral analysis
In the section about needs and actions anticipation, I mentioned that behavioral analysis per se is not necessarily a bad thing. On very large websites, it may be a good thing to see items potentially relevant to you being promoted.
This, however, must be done with particular care:
-
The user must alway remain in control.
Such system should be active only when the user has explicitly logged in, its behavior and impact should be transparent him, the user should have access to the data concerning him and be able to see what attributes are causing certain items to target him and he should have the ability to configure them (at the very least disable this functionality).
-
The data must not be shared with third-party by default.
When data is shared, it must be at the initiative of the user, with his explicit user knowledge and consent, the user being informed of the exact data begin share, the identity of the recipient and the goal of this sharing.
A good example of this is how certain social websites designed their API access, providing an interface where the user explicitely allows the social network to share well defined data with a designed third-party.
-
As seen above, you should not attempt to buy private information about your users, just ask them.
-
You must avoid the creation of a filter bubble.
Promoted and unpromoted content must remain equally accessible, to encourage curiosity, diversity and allow you users to discover new things.
Content delivery networks
Content delivery networks act like cluster of reverse proxies spread all over the world. Instead of reaching the publisher’s server, visitor’s requests go through the CDN system and, as long as the content is available there, the request is replied directly without ever reaching the publisher’s infrastructure.
In theory, a CDN should be used only to accelerate the delivery of static content. In practice, CDNs are often used as a front-end to entire websites. In this condition, the CDN provider has access to the whole content of web pages and all user-submitted data.
 Beyond privacy, this often also opens liability questions as the CDN provider
is often located in a different country or jurisdiction than both the end-user
and the website.
Beyond privacy, this often also opens liability questions as the CDN provider
is often located in a different country or jurisdiction than both the end-user
and the website.
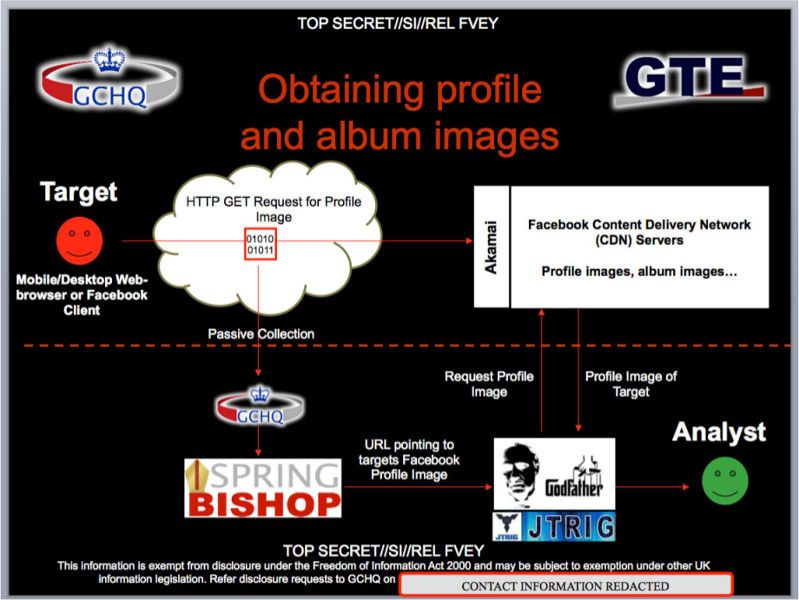
This also open technical issues, as for instance when a user stores or send a private file (a video, a picture, etc.), the file may be accessible to unauthenticated third-party users directly contacting the CDN server with the right URL. This was for instance how the GCHQ‘s program Spring Bishop collected target’s private photographs from Facebook.
At last, the use HTTPS doesn’t help as the TLS tunnel is broken at the CDN level to allow him to do its job. This may be even worse by providing the end-user the wrong feeling that submitted data will only be readable by the recipient service, while the intermediary CDN will have unlimited access to it.
Note
For some time, CDN were used as an free alternative to certification authorities to offer HTTPS access without having to pay for a certificate.
This should not be needed anymore as the Let’s Encrypt project allows you to obtain browser-recognized certificates for free.
There are still a few side-cases11 where you do not have any control over the HTTP server and can use this “trick” to at least secure the section between the visitor and the CDN infrastructure, but such situation is usually less than ideal.
Websites relying on CDN services should therefore at least use two different domain names, each one using different certificates and TLS keys:
-
Either use a specific domain for data served through a CDN (
cdn.example.comfor instance). -
Or use a specific domain to serve pages containing potentially sensitive information which must remain out of the CDN scope (
secure.example.comfor instance).
Note
Prefer to use a subdomain, as shown in the examples above, rather than a
completely different domain name (example-static.com).
This allows to demonstrate that the domain is legit while the latter one is indistinguishable from a phishing attempt12.
Due care must still be taken as this measure alone won’t prevent all data from leaking from one domain to another (URLs parameters present in the Referer header for instance).
Conclusion
While online users tracking is tightly linked to services dear to a lot of webmasters, such as but not limited to online advertisement, the truth is that those “free” (and sometime even paid) services are just the storefront of a huge and uncontrolled economy unrelated to the officially proposed service and which completely despise any notion of privacy or respect toward both users and webmasters which are just puppets and targets allowing to gather money and power.
Web users tracking is just a blatant example of how technology can and will be abused as soon as there is enough profit to be done. Hopefully, it is still possible to say no to this, and I think it is the responsibility of everyone to do so to reduce such profits so we can progress toward a saner and safer Internet.
-
Mostly for thick clients and mobile applications. Depending on the application, the content of crash report may by itself raise some privacy issues. ↩
-
In this context, Google uses the term “creatives” and “ads” alternatively with the same meaning. ↩
-
I like the explanation from Mozilla which describes the DNT header as “a vote for privacy”. ↩
-
The content isn’t usually sent in clear form but as a hash, enough for tracking purposes while reducing legal exposure, but as long as the hash value can be linked to a unique profile on the trackers’ side it practically boils down to the same thing. ↩
-
Emojis must not be confused neither with emoticons such as “:)” which are used for the same purpose but use several characters, nor with the picture files used by some WYSIWYG editors as a graphical replacement for emoticons. ↩
-
A notable example of multiple devices running exactly the same software stack is privacy-oriented operating systems such as Tails or Whonix when they are running on a physical machines. In such cases it is mandatory to ensure that special measures have been taken to either disable JavaScript or at least canvas support. ↩
-
If you are tech-savy and have your own DNS server, you may be interested in building a DNS sinkhole to block such services network-wide. ↩
-
If you have to invoke third-party content in an iframe, at least always ensure that you take advantage of the HTML5 sandbox feature. This will not solve all privacy concerns, but at least limit the power you give to the third-party on your website. ↩
-
When using progressive filling, instead of showing a large and deterring form to your users, just ask a few questions each time they open a session or at different steps of the website usage to complete the user’s profile. ↩
-
Like GitHub pages for instances… ↩
-
Some browsers hardening tools such as uMatrix block them by default. ↩



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}